Hermes 对接企业微信发送文件失败:一次踩坑复盘
一、背景
最近在用 Hermes 做一个企业微信机器人,把 AI 能力接入到真实业务里(客服、自动回复、文件处理这些)。
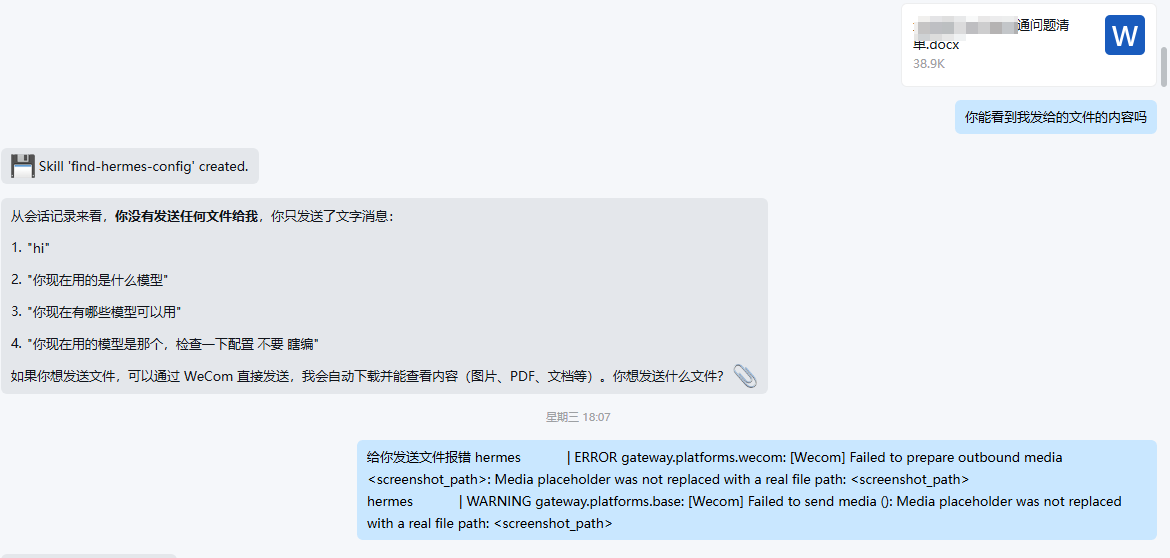
文本消息一切正常,但一到文件/图片就出问题:
- 用户在企业微信发文件 → Hermes 收不到
- 或 Hermes 回发文件 → 报错失败
典型报错:
Media placeholder was not replaced with a real file path: <screenshot_path>
当时第一反应是:
👉 “是不是配置没写对?”
结果一查,完全不是这么回事。
二、问题定位
先明确现象:
| 场景 | 结果 |
|---|---|
| 发送文本 | 正常 |
| 发送图片 | 失败 |
| 发送文件 | 失败 |
| Hermes 日志 | 找不到文件路径 |
1️⃣ 第一层排查:是不是没拿到文件?
去看 Hermes 源码(wecom.py),关键函数:
async def _cache_media(self, kind, media):
里面只处理了两种情况:
base64
url
也就是说:
👉 Hermes 只认:
- base64 文件
- URL 文件
2️⃣ 第二层排查:企业微信到底传了什么?
抓企业微信回调数据,发现:
{
"msgtype": "file",
"media_id": "xxxx"
}
👉 关键点来了:
企业微信不会直接给你文件内容,只给你一个 media_id
3️⃣ 第三层排查:Hermes 是否处理 media_id?
答案是:
❌ 完全没有处理
代码里:
url = str(media.get("url") or "").strip()
if not url:
return None
👉 没有 url → 直接 return None
👉 文件直接被“静默丢弃”
三、问题本质
一句话总结:
Hermes 不支持企业微信的 media_id 文件机制
完整链路是这样的:
企业微信 → media_id → ❌ Hermes没下载 → ❌ 没文件 → ❌ 无法发送
四、解决方案
核心思路:
👉 把 media_id 转成真实文件
Step 1:调用企业微信接口下载文件
接口:
POST https://qyapi.weixin.qq.com/cgi-bin/aibot/media/get
参数:
{
"robot_id": "...",
"secret": "...",
"media_id": "xxx"
}
返回:
👉 二进制文件流(不是 JSON)
Step 2:保存到本地
例如:
/tmp/file.docx
Step 3:交给 Hermes
{
"type": "file",
"path": "/tmp/file.docx"
}
五、代码修改(关键)
在 wecom.py 的 _cache_media 中增加:
media_id = str(media.get("media_id") or "").strip()
if media_id:
raw, content_type = await self._download_media_by_id(media_id)
return cache_document_from_bytes(raw, "wecom_file"), content_type
并新增:
async def _download_media_by_id(self, media_id):
resp = await self._http_client.post(
"https://qyapi.weixin.qq.com/cgi-bin/aibot/media/get",
json={
"robot_id": self._bot_id,
"secret": self._secret,
"media_id": media_id,
},
)
return resp.content, resp.headers.get("content-type")
六、排查过程总结
这次问题其实挺典型的,踩坑点在这几个地方:
❌ 误区 1:以为是配置问题
→ 实际是源码没支持
❌ 误区 2:以为 Hermes 会自动处理文件
→ 实际只支持 base64 / url
❌ 误区 3:没理解企业微信机制
→ 企业微信用的是 media_id,不是文件
七、最终结论
👉 不是你不会用 Hermes
👉 是 Hermes 目前版本没支持企业微信文件
八、延伸建议
如果你也在做类似集成,建议直接这样设计:
WeCom → media_id → 下载 → 本地文件 → AI处理 → 再发送
而不是依赖 Hermes 自动处理。
九、一句话总结
👉 Hermes 不会帮你下载文件,它只会发送“已经存在的文件”
正文到此结束
- 本文标签: hermes
- 版权声明: 本文由HARRIES原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
- 本文海报: 生成海报一 生成海报二
热门推荐







相关文章




Loading...
![[HBLOG]公众号](https://www.harries.blog/img/qrcode_gzh.jpg)

