数据库第一次怎么建
第一次做产品时,很多人会卡在数据库设计上。用户表要不要拆?订单表怎么写?项目、任务、日志、配置要不要一开始都建?字段是不是以后会变?如果现在设计错了,后面会不会很难改?
数据库当然重要,但第一版数据库不需要完美。它最重要的任务,是支撑核心流程稳定跑通,同时给未来变化留出空间。你不是在设计一个永远不变的终极模型,而是在设计一个可以随着产品验证不断演进的数据结构。
早期数据库设计的目标只有三个:核心对象清楚,关键关系正确,重要状态可追踪。做到这三点,比一开始堆很多表更重要。
从用户流程倒推数据对象
数据库不要从“我应该有哪些表”开始,而要从用户流程开始。
先写出用户完成核心结果的路径:用户注册,创建项目,提交输入,生成结果,查看结果,导出结果,可能付费升级。然后问每一步会产生什么数据,哪些数据需要长期保存,哪些只是临时状态。
比如一个 AI 报告产品,核心对象可能只有用户、报告、报告输入、生成任务、订阅。早期不一定需要团队表、标签表、评论表、复杂审计表。只要核心流程能跑通,就可以先小。
如果一个对象没有出现在主流程里,先不要急着建表。很多提前设计的表,最后会因为产品方向变化而完全用不上。
数据库的第一原则是:先存核心业务事实,不存想象中的未来功能。
先识别核心实体
核心实体是产品里最重要的名词。通常包括用户、项目、内容、任务、订单、订阅、文件、配置等。不是每个产品都有这些,但大多数 SaaS 都会有其中几个。
你可以用一个简单问题识别实体:这个东西是否需要被创建、查询、修改、删除、关联、计费或追踪状态?如果是,它可能是一个实体。
比如“报告”是实体,因为它要被创建、查看、导出、归属于用户;“生成中”不是实体,而是任务或报告的状态;“高级模型”通常不是实体,可能只是配置或枚举;“用户填写的一次表单”是否是实体,要看你是否需要长期保存和复用。
不要把所有名词都建成表。表越多,关系越复杂。第一版只保留核心实体,把不稳定的细节放在字段或 JSON 里,等需求稳定后再拆。
关系比字段更重要
字段可以改,关系改起来更痛。所以第一次建数据库时,要先想清楚对象之间的关系。
常见关系有:一个用户有多个项目,一个项目有多个任务,一个任务生成一个结果,一个用户有一个当前订阅,一个订单属于一个用户,一个文件属于一个资源。
这些关系决定了数据归属和权限边界。比如报告属于用户还是项目?订单属于用户还是团队?文件是否可以被多个报告复用?如果关系设计混乱,后面权限、计费和后台管理都会变复杂。
早期不要过度抽象。个人产品可以先让资源直接归属于 user_id。等团队协作真实出现,再引入 workspace_id 或 team_id。为了未来想象提前上多租户,会让第一版变重。
状态字段要设计清楚
很多产品问题来自状态混乱。任务到底是 pending、processing、success 还是 failed?订单是 paid、refunded、canceled 还是 past_due?报告是 draft、ready、archived 还是 deleted?
状态字段要少而清楚。每个状态都要有明确含义和允许的流转。不要随手加状态,也不要用多个布尔字段表达同一件事,比如 is_paid、is_canceled、is_refunded 同时存在,很容易组合出矛盾状态。
更好的方式是用一个主状态字段,再配合时间字段和原因字段。比如 status = failed,failed_at,failure_reason。这样既能表达当前状态,也能帮助排错。
对于异步任务、支付、邮件发送、文件上传这类流程,状态设计尤其重要。你要能知道它现在在哪一步,为什么失败,能不能重试。
时间字段和软删除不要省
第一版数据库至少要保留 created_at 和 updated_at。这两个字段看起来普通,但对排查问题、排序、统计、后台管理都非常有用。
很多核心表还应该考虑 deleted_at。软删除不是所有表都必须有,但用户内容、项目、报告、订单这类重要数据,直接物理删除风险很高。软删除可以让你恢复误删,也能保留审计线索。
当然,软删除也会增加查询复杂度。你需要确保默认查询过滤已删除数据,并在后台或管理工具里明确显示。不要一边软删除,一边忘记在业务查询里加条件。
时间字段和删除策略属于基础工程卫生。早期做对,后面省很多麻烦。
JSON 字段可以用,但不要滥用
早期需求不稳定时,JSON 字段很好用。比如 AI 生成参数、第三方回调原始数据、报告结构、用户偏好、实验配置,都可以先用 JSON 存起来。
但 JSON 不应该替代核心字段。凡是经常查询、筛选、排序、关联、统计、加权限判断的内容,都应该成为明确字段。比如用户 ID、状态、套餐、价格、创建时间、资源归属,不要藏在 JSON 里。
一个实用原则是:不稳定但不常查询的细节,可以放 JSON;稳定且经常参与业务判断的数据,应该拆成字段。
JSON 是帮助你快速迭代的缓冲区,不是逃避数据建模的万能袋子。
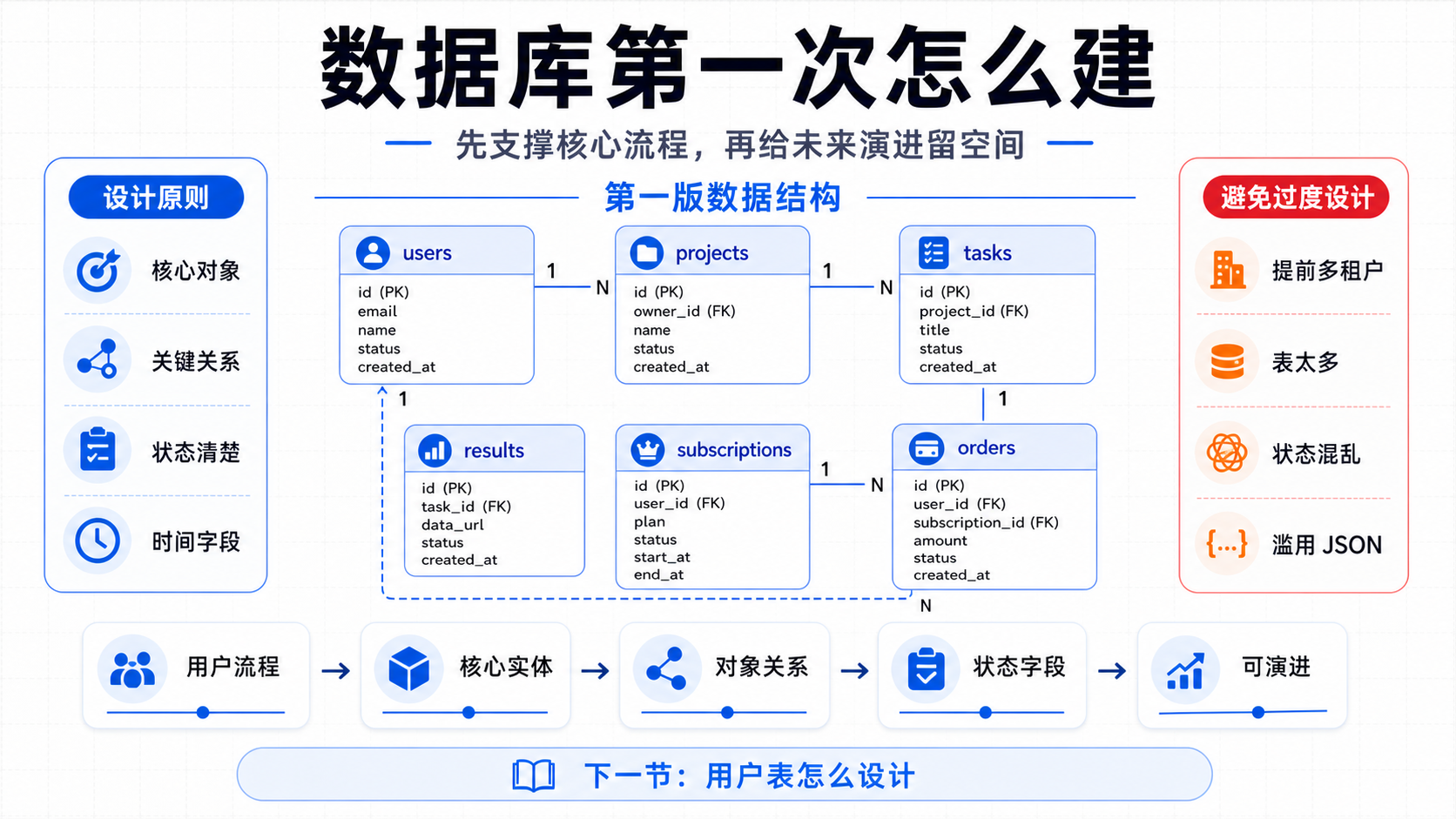
第一版数据库模板
一个典型早期 SaaS 可以从这些表开始:
users
- id, email, name, avatar_url, auth_provider, created_at, updated_at
projects
- id, user_id, name, status, created_at, updated_at, deleted_at
tasks
- id, user_id, project_id, type, status, input_json, output_json, error_message, created_at, updated_at
results
- id, user_id, project_id, task_id, title, content_json, status, created_at, updated_at, deleted_at
subscriptions
- id, user_id, plan, status, provider, provider_customer_id, current_period_end, created_at, updated_at
orders
- id, user_id, subscription_id, amount, currency, status, provider_order_id, raw_payload_json, created_at
这不是所有产品都要照抄的结构,但它展示了几个关键点:用户归属清楚,任务状态可追踪,结果可以独立管理,支付数据和用户绑定,第三方原始数据可保留。
如果你的产品更简单,可以砍掉 projects 或 subscriptions。如果你的产品有团队,再增加 workspaces 和 memberships。结构应该服务业务,而不是套模板。
总结
第一次建数据库,不要追求一次性完美。先从用户流程倒推核心实体,想清对象关系,设计清楚状态,保留时间字段和必要审计信息。稳定的数据做字段,不稳定的细节可以先用 JSON 缓冲。
好的第一版数据库应该让产品能跑、问题能查、结构能改。它不需要覆盖所有未来功能,但要避免把核心关系和状态做错。只要核心对象清楚,后面演进就不会太痛。
作业
- 写出你的产品核心流程会产生的所有数据。
- 标出其中必须长期保存的核心实体。
- 为每个实体写出归属关系,比如属于用户、项目还是团队。
- 为任务、订单或内容设计一个主状态字段。
- 检查核心表是否包含 created_at、updated_at 和必要的 deleted_at。
下一节课
用户表怎么设计:用户表不是越多字段越好,而是要稳定承载身份、状态、权益和后续扩展。
正文到此结束
- 本文标签: 数据库
- 版权声明: 本文由HARRIES原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
- 本文海报: 生成海报一 生成海报二
热门推荐







相关文章

近期评论
-
https://docs.openclaw.ai/zh-CN/install/docker
-
-
开发完毕,订阅地址:https://www.harries.blog/feed
-
-
虽然已经是22世纪了,但是能否加一个RSS功能?
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
Loading...
![[HBLOG]公众号](https://www.harries.blog/img/qrcode_gzh.jpg)

